2030 基于豆包、Claude识别的中国 A 股人工智能领域企业数据 2010-2024
| 数据来源 | 中国 A 股上市公司官方网站、上市公司年度报告等。 |
| 时间跨度 | 2010-2024 年 |
| 区域跨度 | 中国 A 股上市公司 |
| 数据格式 | 数据格式为Excel形式 |
在智能技术快速发展的浪潮中,通过企业的经营范围文本精准识别中国 A 股市场中属于人工智能领域的企业,是深入探究该领域发展规律、评估产业发展潜力的关键前提。其重要性不仅体现在为学术研究提供可靠的样本基础,也为企业战略制定、市场监管等实践工作提供有力的数据支撑。
人工智能企业是以人工智能技术为核心驱动力,致力于研发和应用机器学习、深度学习、自然语言处理等智能算法,实现模拟人类智能进行决策、推理、识别等功能,像从事人工智能算法研发、智能系统集成、智能机器人研发等业务的企业便属于此类,其核心在于让机器具备类似人类的智能能力。
本数据中用于依据企业经营范围文本判断其是否为人工智能企业的核心指标构建过程如下:数据来源于中国 A 股上市公司的官方网站、年度报告等公开渠道。借助豆包(doubao-1-5-pro-32k-250115)和 Claude (claude-sonnet-4-20250514)两个大型模型,分别对企业的经营范围文本内容进行识别,综合两者的判断结果,确定该企业是否为人工智能领域的企业,最终获得 2010-2024 年的相关数据。
与使用 XGBOOST、BERT 等机器学习模型基于经营范围文本进行判断的方式相比,本方法优势显著。XGBOOST 作为基于树模型的算法,高度依赖人工特征工程,对于企业经营范围这类复杂文本,人工提取特征不仅耗时费力,还易遗漏关键信息,导致其对复杂语义的理解能力受限,难以精准识别人工智能领域的企业。BERT 虽在自然语言处理领域表现较好,但在泛化性和对非规范文本的处理上存在不足,面对企业经营范围中涉及人工智能领域的模糊表达、行业特有术语等,准确性会受影响。而豆包和 Claude 具备强大的自然语言理解与生成能力,无需复杂的特征构建,能深度解读企业经营范围文本中的语义信息,对涉及人工智能领域的模糊、非规范表述有效理解,从而更精准判断企业是否为人工智能领域企业。
选择豆包和 Claude 进行判断,原因在于豆包是一款先进的语言模型,在中文语义理解方面优势突出,能精准把握中国上市公司各类文本中复杂的经营范围表述,尤其对涉及人工智能领域的内容有良好的解读能力,契合国内市场的语言习惯和业务场景。Claude 是一款知名的大型模型,在多领域应用广泛,对不同业务场景的经营范围理解能力较强,且在多语言处理上有一定优势,能辅助识别人工智能领域企业。二者结合,可从不同角度对企业经营范围文本深入分析,形成互补,降低误判概率,提升判断结果的准确性和全面性。
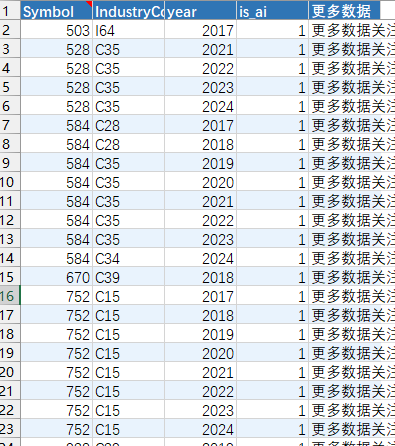
Symbol | IndustryCode | year | is_ai |
因数据量较大,此处仅展示部分示例数据