2284 上市公司绩效期望盈余【PAS】(2010—2024)
| 数据来源 | 本数据集原始数据来源于中国上市公司财务数据及企业年度报告 |
| 时间跨度 | 2010年至2024 |
| 区域跨度 | 全部A股上市公司(已剔除金融业、ST、PT及数据缺失或异常的公司) |
| 数据格式 | Excel形式 |
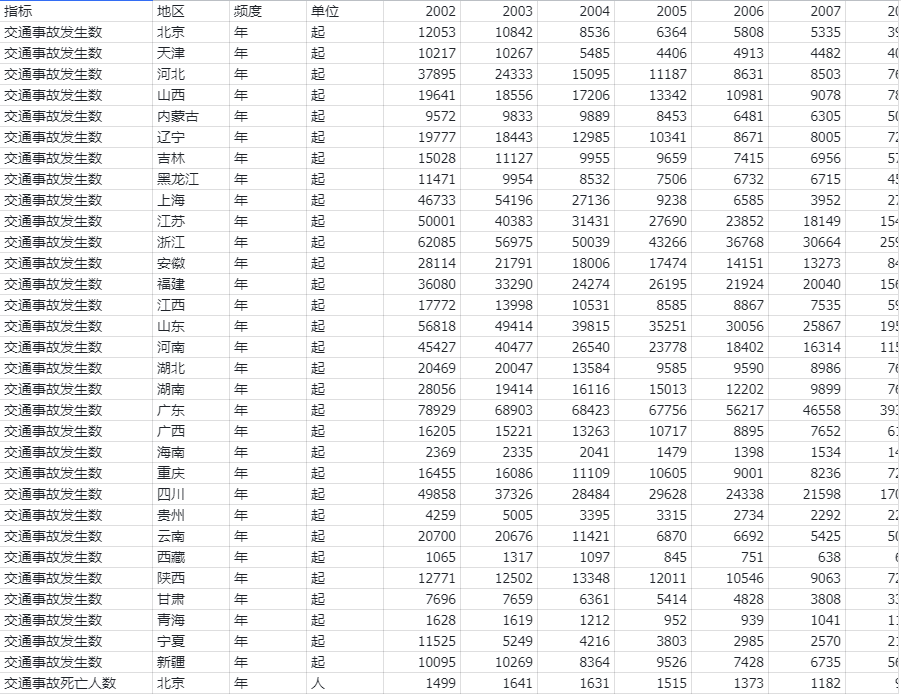
本数据集基于中国A股上市公司财务数据构建,涵盖2010—2024年间全部A股上市公司(已剔除金融业、ST、ST*、PT类公司以及数据缺失或异常样本),并进行缩尾处理,最终获得数万条公司—年度观测值。数据来源于CSMAR数据库,并在原始财务指标基础上,依据行为企业理论构建了绩效期望盈余(PAS)指标。数据集包含以下字段:企业代码、企业简称、年份、资产回报率(ROA)、行业代码;衍生指标包括:历史期望水平(企业前两年ROA的算术平均值)、行业总ROA(同行业同年份所有公司ROA之和)、行业公司数(同行业同年份公司总数)、行业平均ROA(剔除企业自身后的同行业同年份平均ROA)、期望绩效(A,由历史和行业期望水平加权合成)、期望值差(实际ROA与期望绩效之差)、二元虚拟变量(I,实际绩效是否超过期望绩效,超过取1否则取0),以及最终核心指标——绩效期望盈余(PAS = I × 期望值差)。该指标既捕捉了企业是否处于高绩效状态,又度量了超出期望的具体幅度,能够有效刻画企业的高绩效程度。
基于本数据集可展开以下三方面研究:一是绩效反馈与企业创新行为——借助PAS指标分析当企业实际绩效超过历史及行业期望水平时,其资源分配策略、风险偏好及创新行为的变化规律,检验“富裕驱动探索”或“绩效引致惰性”等理论假说,拓展行为理论在企业层面的应用边界;二是数字化转型的调节效应——可结合企业年报文本分析,构建生成式人工智能(GAI)采用程度指标,探究GAI如何强化或弱化PAS对资源分配新颖性及创新质量(如专利引用)的传导路径,揭示技术赋能机制;三是制度环境与异质性分析——考察不同产权性质(国企/民企)、市场竞争程度、地区市场化水平下,PAS对企业战略决策的差异化影响,为理解中国制造业企业高质量发展提供实证依据
指标构建具体步骤如下
PAS的测度借鉴Chen(2008)的研究框架,兼顾历史与行业双重基准。首先,计算企业i在t年的历史期望水平![]() ,即前两年(t-1和t-2)ROA的算术平均值;行业期望水平
,即前两年(t-1和t-2)ROA的算术平均值;行业期望水平![]() 则为t年同行业(除i外)所有公司ROA的均值。期望绩效
则为t年同行业(除i外)所有公司ROA的均值。期望绩效![]() 由二者加权合成:
由二者加权合成:![]() ,权重系数α取0.6,该参数源自Chen(2008)的实证设定。其次,构造二元虚拟变量
,权重系数α取0.6,该参数源自Chen(2008)的实证设定。其次,构造二元虚拟变量![]() ,若实际绩效
,若实际绩效![]() (即ROA)大于
(即ROA)大于![]() 则取1,否则取0。最后,绩效期望盈余定义为
则取1,否则取0。最后,绩效期望盈余定义为![]() 。所有基础财务指标均来源于CSMAR数据库,经清洗、匹配与缩尾后形成本数据集。
。所有基础财务指标均来源于CSMAR数据库,经清洗、匹配与缩尾后形成本数据集。
企业代码 | 企业简称 | 年份 | ROA |
行业代码 | 历史期望水平 | 行业总_roa | 行业公司数 |
行业平均_roa | 期望绩效 | 期望值差 | 二元虚拟变量 |
绩效期望盈余(PAS) |
[1] Luo, X., Yu, D., & Zhou, D. (2026). Does AI catalyze novelty? Generative AI, resource allocation novelty, and innovation quality of high-performing manufacturing enterprises in emerging markets. Technovation, 153, 103525. https://doi.org/10.1016/j.technovation.2026.103525