2319 AI能力基准评测数据 (2012-2026)
| 数据来源 | 斯坦福大学以人为本人工智能研究所(Stanford HAI)《2026年人工智能指数报告》技术性能章节基准测试数据 |
| 时间跨度 | 2012-2026 |
| 区域跨度 | 全球主流大语言模型及多模态模型 |
| 数据格式 | CSV/pdf形式 |
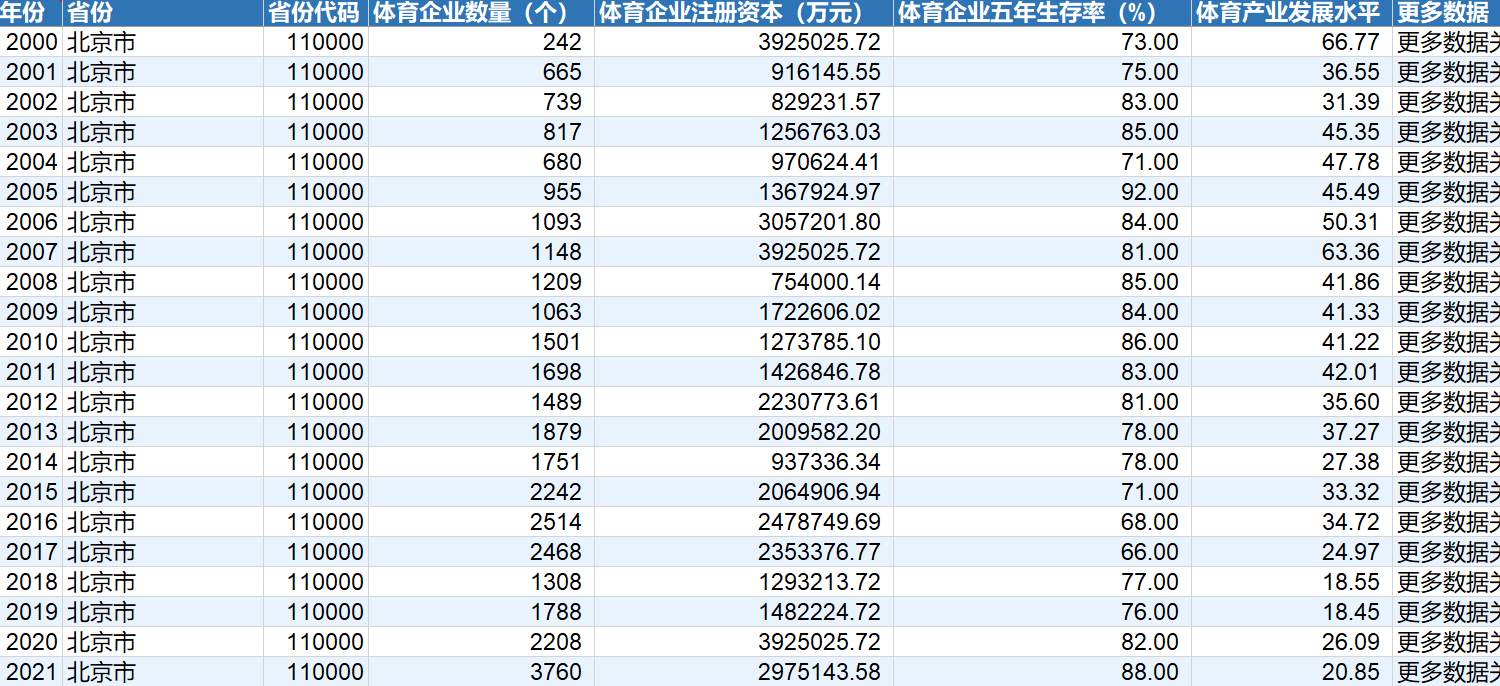
本数据基于斯坦福大学人工智能研究所(HAI)发布的《2026年人工智能指数报告》第二部分“技术性能”中的核心基准评测结果整理而成。该部分系统追踪了人工智能在多领域任务上的性能演进,通过标准化测试集(如MMLU、MATH、HumanEval、GPQA、VQAv2等)量化评估了AI模型在语言理解、数学推理、代码生成、专业问答及视觉问答等方面的能力水平。核心视角在于揭示AI技术发展的"锯齿前沿"(Jagged Frontier)特征——即模型在高阶抽象推理任务上已达到甚至超越人类专家水平,却在基础感知类任务上表现参差不齐,呈现能力发展的不均衡性。
基于此可展开多方面研究:一是能力演进异质性研究,分析AI在博士级科学问答、竞赛数学、代码生成等复杂任务与模拟时钟识别、物理常识推理等基础任务间的表现落差,探究模型架构、训练数据分布与任务本质对能力涌现的差异化影响机制;二是技术迭代速度研究,追踪关键基准测试(如SWE-bench Verified、MMLU、HumanEval)的性能突破时间窗口,识别AI能力加速演进的临界点与饱和区间;三是人机能力边界研究,对比AI与人类基线在标准化考试、多模态推理等场景的表现差异,量化"人机对齐"与"超越"的判定标准与转换条件;四是产业应用风险评估,基于能力"偏科"现象识别当前AI系统在真实场景部署中的可靠性缺口,为技术落地提供审慎性依据。
本数据反映了当前AI发展的核心矛盾:模型在2025-2026年间实现了能力跃升——在博士级科学问题、国际数学奥林匹克竞赛级别题目上达到人类顶尖水平,编程基准测试准确率从60%飙升至接近100%;然而,在模拟时钟读数、日历问答等人类视为本能的视觉-空间任务上,顶级模型的准确率仍徘徊在50%左右,暴露了其视觉理解能力的结构性短板。这种"高阶强、基础弱"的能力分布,提示当前AI系统在抽象符号推理与具身物理感知之间存在深层的架构性断层。
六、Year | Method | Perfomance relative to the human baseline |
Benchmark | Task | 相关图表 |
指标解释
测试任务类别 | 具体指标 | 人类基准对比 |
标准化考试表现 | MMLU(大规模多任务语言理解)、GPQA(博士级科学问答)得分 | 人类专家/普通成人对比组 |
数学推理能力 | 竞赛数学(Olympiad级别)准确率、高中数学解题成功率 | 人类竞赛选手平均水平 |
代码生成能力 | SWE-bench Verified通过率、HumanEval代码正确率 | 人类软件工程师基线 |
视觉感知任务 | 模拟时钟读数准确率(Analog Clock Reading) | 人类儿童/成人对比组 |
日历推理任务 | 日历问答任务准确率(Calendar QA) | 人类日常推理基线 |
时间理解能力 | 识别模拟时钟并读出时间的能力(Time Understanding) | 人类基础视觉-时间认知 |
[1] Stanford University. (2026). Artificial Intelligence Index Report 2026. Stanford Institute for Human-Centered Artificial Intelligence (HAI).