1810 中国气候变化政策严格度(1954-2022)
| 数据来源 | 由数据皮皮侠团队人工整理 |
| 时间跨度 | 1954-2022 |
| 区域跨度 | 全国范围 |
| 数据格式 | 数据格式为excel形式 |
在当今,全球气候政策已取得显著进展,体现于广泛覆盖、多元机制及日益提升的政策效能。实现温控目标需系统化政策组合,以平衡气候、社会和经济协同效应。研究表明,政策有效性取决于合理组合,而非数量。传统气候政策分为减缓(减少温室气体排放)与适应(降低风险、抓住机遇),但这一分类过于狭隘,忽视了许多非直接针对气候变化却能增强系统韧性的政策。
自1953年第一个五年计划启动以来,中国的煤炭消费、温室气体排放和GDP持续增长,能源密集型工业化显著。中国在1990年代前已积累丰富实践,可视为现代气候治理先驱。制定多目标导向的气候政策需依赖本地经验,而单一的气候政策定义已不足以全面反映中国国家行动与历史政策实践的广度。
因此,Bo Li和Enxuan Xu等(2025)所提出并定义的气候变化政策严格性(PSCC),来衡量所有对气候变化有积极影响的政策严格程度,无论其主要目标是否聚焦气候变化。该定义从客观后验视角拓展了气候政策理论,支持测量、因果推断及综合政策组合构建。
数据处理过程如下:
1. 确认数据源:
8个数据来源:中国国务院公报档案系统,国务院政策文件库,中国政报公报期刊文献总库,北大法宝,全球气候变化减缓政策数据库,中国低碳政策强度数据集,中国环境政策强度数据集,中国共产党大事记
2. 数据采集:
- 构建元数据数据库,当中记录每条政策的关键信息 (详见数据指标)
- 基于使用RSelenium进行任务导向型网络爬虫
最终建立两大基础数据库,元数据数据库和政策库
3. 数据预处理
a) 多源数据标准化
对多种格式的数据(包括 PDF、TXT、DOC 和 JPG 文件)进行标准化处理,提取文本内容,统一转换为 TXT 文件。过程中使用 R 语言中的正则表达式(Regex) 进行文本清理,同时在处理过程中去除多余空格、符号、英文数字及其他噪声元素,并最终将文本整理为连贯、标准化格式,确保句子按顺序排列,无冗余符号或空格
b) 基于大语言模型(LLM)的筛选与分类系统
选择GPT-4o 作为主要分类模型,并使用 Qwen-72B 作为提示增强(prompt augmentation)模型,两者均可通过第三方 API 访问,以支持政策筛选与分类任务。
n 首要任务是筛选出具有减缓或适应气候变化潜力的政策
n 随后按照其政策工具类型进行分类,包括命令与控制型工具,如法律法规等强制性政策;市场化混合工具,如资金支持、税收政策、国际合作等经济激励措施;自愿性工具,如公众意识宣传、教育倡议等间接政策
u 分类过程中采用系统化的 LLM 策略,结合提示学习、上下文学习、指令学习及思维链推理,先提示工程优化,再手动标注训练集,接着引入 Qwen 作为提示增强模型,然后迭代优化提示词,最终筛选和分类
c) 整理文档-术语矩阵(DTM)
在二次筛选后的政策池基础上,将其转换为文档-术语矩阵(Document-Term Matrix, DTM)格式,其中每一行代表一个文档(如一条政策文件);每一列代表一个术语(term);矩阵中的值通常表示该术语在该文档中的出现次数。
4. 气候变化政策严格程度(PSCC)评估
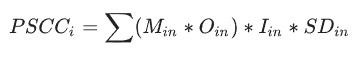

![]()
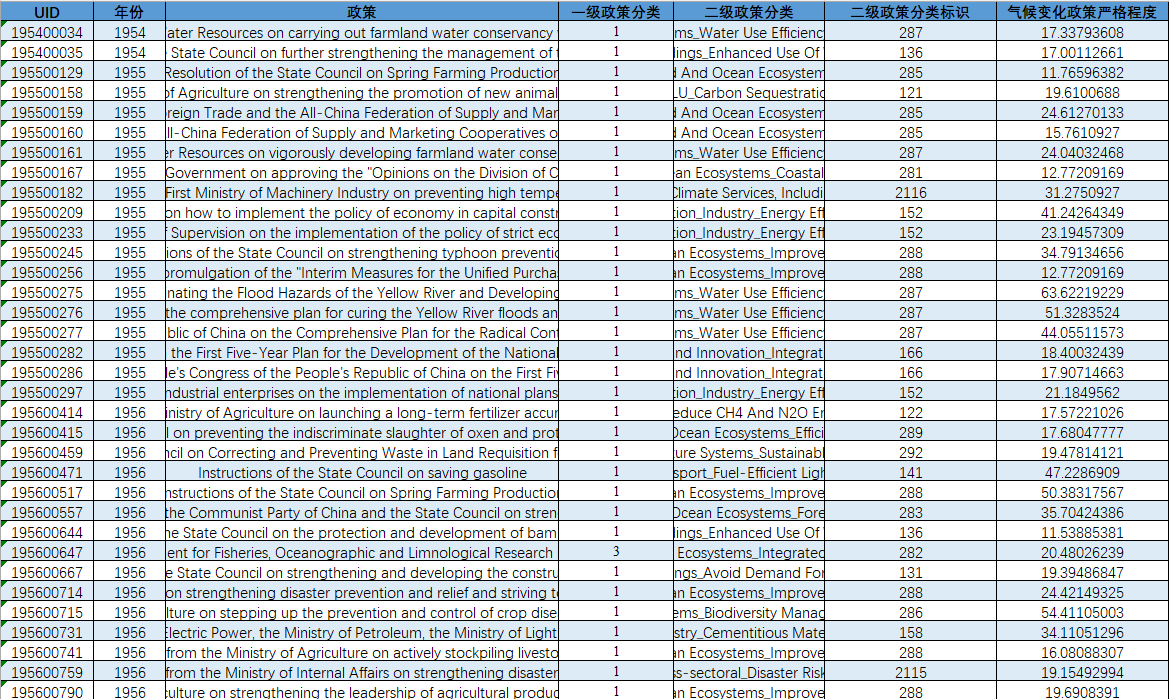
字段名称 | 字段描述 |
UID | 唯一标识符(UID)用于区分单个政策 |
年份 | 政策颁布或实施的年份 |
政策 | 政策名称 |
一级 政策类型 | 1=命令与控制工具类型政策;2=市场化和混合工具类型政策;3=自愿工具类型政策 |
二级政策类型 | 维度归属,同二级分类基于词典系统设计,旨在将政策内容与最可能相关的子维度匹配。 |
二级政策类型标识 | 以数字格式表示的简称 |
气候变化政策严格程度 | 总体气候变化正常严格性评分 |
Li, B., Fu, E., Yang, S. et al. Measuring China’s Policy Stringency on Climate Change for 1954–2022. Sci Data 12, 188 (2025). https://doi.org/10.1038/s41597-025-04476-0