1897 年报风险信息披露模仿行为(2000-2023)
| 数据来源 | 由数据皮皮侠团队人工整理,全部内容真实有效 |
| 时间跨度 | 2000-2023年 |
| 区域跨度 | 中国上市公司 |
| 数据格式 | 数据格式为Excel形式 |
数据简介
中国上市公司在风险信息披露中可能采用策略导致投资者风险感知不升反降,这一现象值得深入探究。上市公司在披露风险时存在同行模仿行为。这种模仿行为主要出现在盈余波动性高、非行业龙头以及存在控股股东股权质押的公司,且在高经济政策不确定时期更为常见。通过同行模仿,上市公司能够有效降低投资者和分析师对其风险的感知水平。研究这一行为有助于挖掘风险信息文本,解释中国上市公司风险信息披露为何会降低投资者风险感知,进而为监管层和投资者理性解读上市公司风险信息提供理论依据,保障资本市场的健康和稳定。
本团队参考王成龙和吴忧(2024)的文章,按照如下步骤计算模仿性主题得分:
1. 文本预处理:以 A 股上市公司年报风险信息文本为语料库,删除停用词、数字、符号,以及在 90% 以上或少于 3 篇文本中出现的词语。
确定最佳主题数:通过 LDA 主题模型在 2-50 区间内计算一致性得分,选取得分最高的 26 作为最佳主题数,并通过气泡图可视化验证主题划分的合理性。
2. 计算主题得分:利用 LDA 模型计算每篇文本中 26 个主题的得分(即各主题在文本中的篇幅占比),所有主题得分之和为 1。
3. 识别模仿性主题:在同行业 - 年内,若某主题被超 50% 公司提及(主题得分 > 0.01),则认定为模仿性主题(不同行业 - 年的模仿性主题可能不同)。
4. 加总模仿性主题得分:对每个公司 - 年的风险文本,将其提及的模仿性主题得分相加,生成最终的模仿性主题得分(Imi_Score)。
数据指标
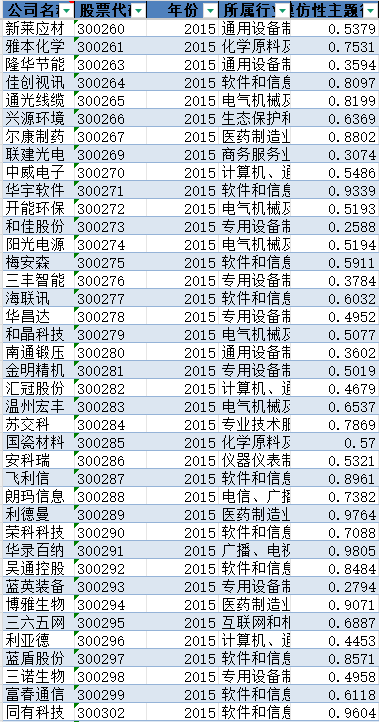
公司名称 | 股票代码 | 年份 | 所属行业 | 模仿性主题得分 |
数据展示
参考文献
[1]王成龙,吴忧.年报风险信息披露模仿行为研究:基于LDA主题模型分析[J].世界经济,2024,47(11):183-205..
下载权限为: 
 兑换码获取
兑换码获取
获取数据 样本下载
中级会员
9折
高级会员
8折
尊享会员
7折